Annotation
A successful machine learning application starts with data.
Although there exist many large open machine-learning datasets, deep neural network (DNN) applications usually require specialized training data and annotation.




FACES IN THE WILD


Data is plentiful but ground-truth annotation can be expensive to create. DNNs are limited by their training data.
Neureon solves the data problem with several strategies:
1: Semi-automatic boot-strap annotation
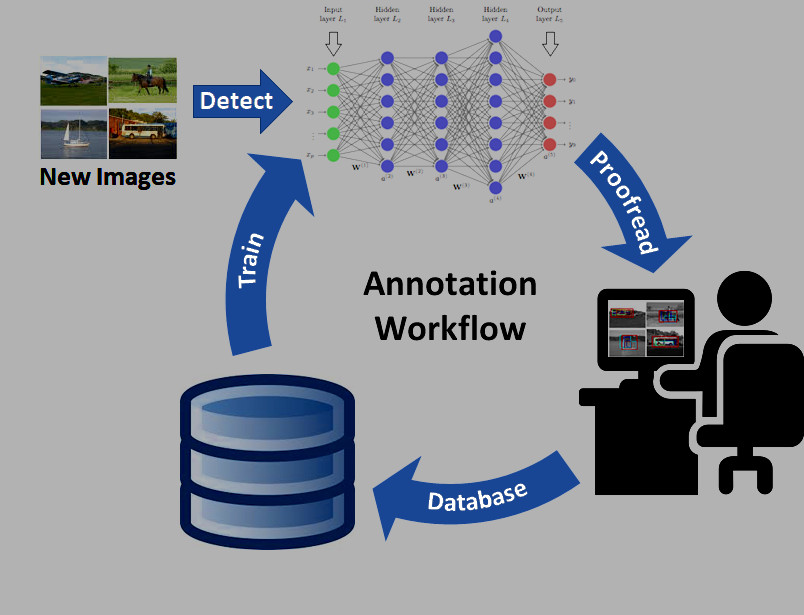
Networks trained on a task automatically annotate new training data. As the training database grows, proofreading effort decreases. Training data continues to grow after the application is deployed.
2: Self annotating video



Moving targets are tracked and stabilized in video. Auto-encoder networks learn to ignore moving distractors.
3: Synthetic ray-traced images and ground truth



Domain randomization mitigates synthetic dataset bias. We render target models on background photographs. High dynamic range images (HDRIs) generate diverse lighting and atmospheric conditions.
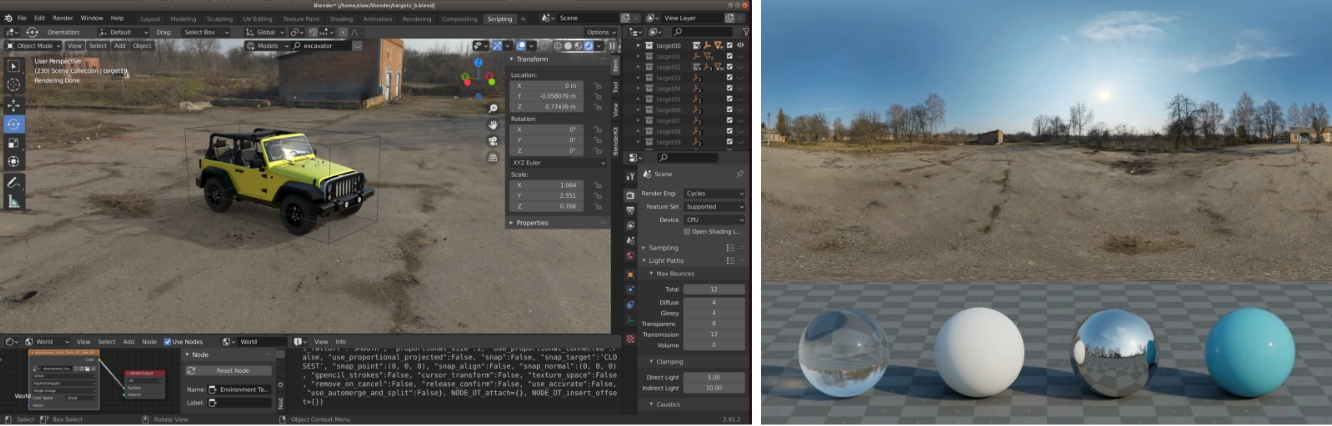
Occlusion augmentation uses alpha blending.

+

=


Our networks trained on synthetic target images




perform well on photos of real targets.

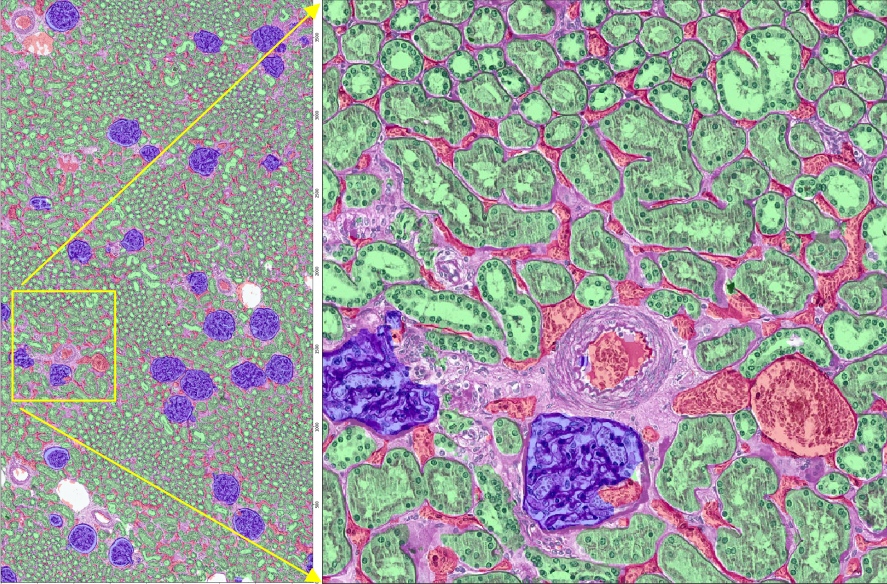
Results: Semantic Segmentation on Real Targets






















